字典是 构建 Redis 底层结构的重要数据结构,比如 命令表 commands、数据库、哈希键 等,尤其数据库部分,对数据库的增、删、查、改都是建立在对字典的操作上
字典 是一种保存键值对的抽象数据结构;在字典中,一个键 key 与 一个值 value 进行关联,组成键值对,一般又称 符号表 / 关联数组 / map 映射等;字典中的键都是独一无二的,程序可以在字典中根据键查找与之关联的值,或者通过键来更新值,又或者根据键来删除整个键值对 等等;通常高级语言都会内置实现好的 字典数据结构,比如 PHP 的关联数组、Java 的 MAP 等都是如此
在 Redis 中,比较典型的例子比如命令 SET foo1 test,即为操作 key 为 foo1 的字典;而 哈希类型的数据,比如 HMSET person name "kety" age 20 weight "75kg" height 20,即为操作 key 为 person 的字典,而 值也是由字典结构数据组成,key=name | key=age | key=weight | key=height
字典 数据结构
Redis 字典模块主要由 dict 、 dictht 、 dictEntry 三个结构组成,当然还有一个标记数据类型的 dictType
由下图可以看出各个数据结构的关系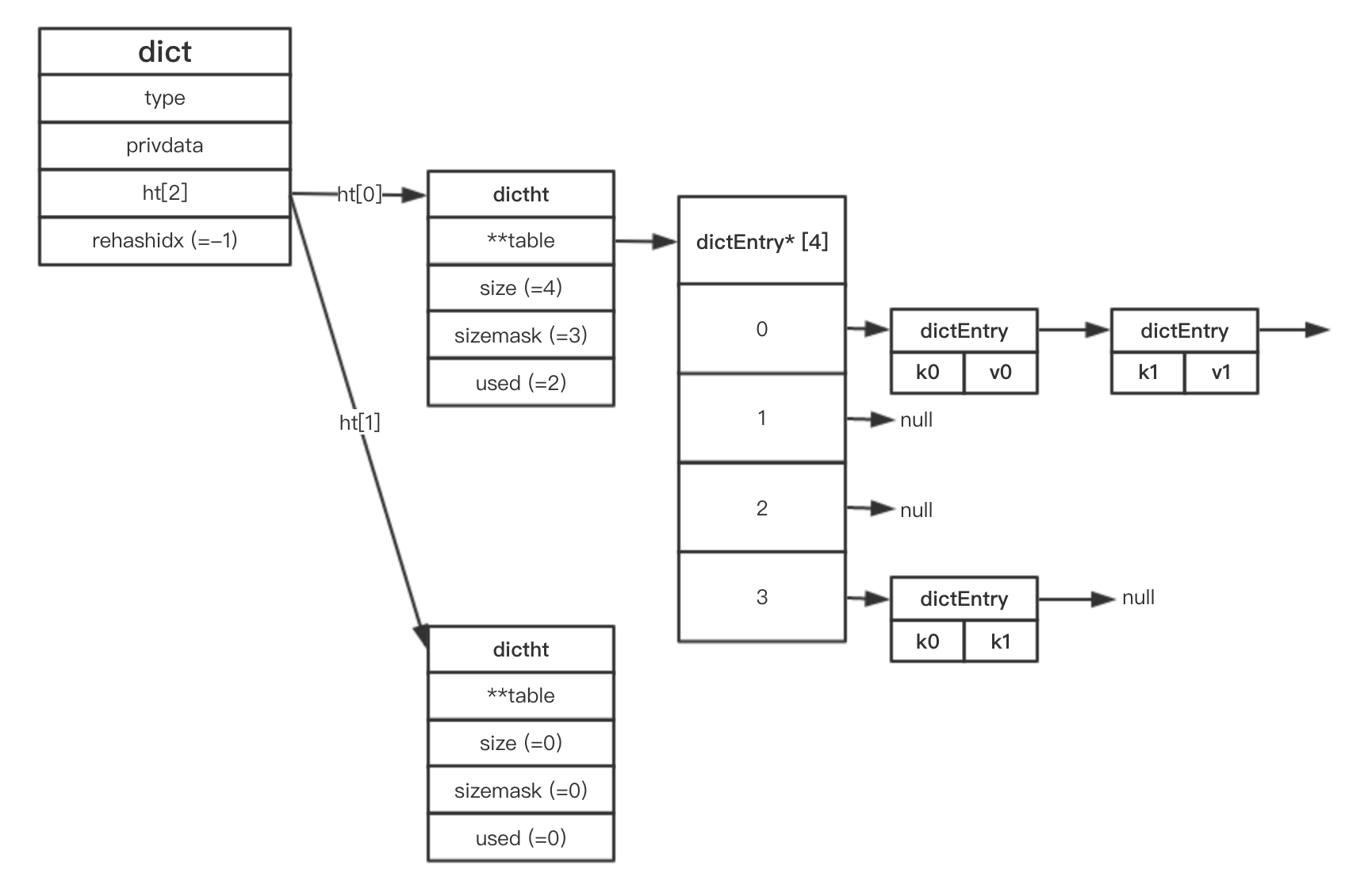
字典 dict 结构 中 ht[0]、ht[1] 每个代表一个 dictht 哈希表,一般情况下只使用 ht[0] 哈希表,只有在 rehash 的时候才使用 ht[1],同时 rehashidx 也记录了当前 rehash 进度,默认没有 rehash 的时候 rehashidx=-1;
而 rehash 操作是因为 随着操作不断的执行 保存的键值对不断增多或者减少,为了保证 负载因子( load factor = ht[0].used / ht[0].size ) 始终维持在一个合理的范围内,当 键值对数量太大或者太小 的时候 对 哈希表进行 扩展或者 收缩;rehash 的步骤如下:
- 为 ht[1] 哈希表分配空间,分配空间大小取决于 要执行的操作,以及 ht[0] 键值对数量(ht[0].used);如果执行的是扩展操作,那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2 的 2n;如果执行的是收缩操作,那么 ht[1] 的大小为第一个大于等于 ht[0].used 的 2n
- 将所有 ht[0] 中的键值对 rehash 到 ht[1] 上,rehash 就是重新计算哈希值和ht[1] 上的位置
- 当 ht[0] 上的所有键值对都转移到 ht[1] 上的时候,释放 ht[0] 空表,将 ht[1] 命名为 ht[0],重建空白 ht[1],等待下一次 rehash
- rehash 的过程跟我们的教程一样,都是 渐进式的,分多次的,特别是 有 上亿键值对的时候
- 为 ht[1] 分配空间,同时持有 ht[0] 和 ht[1] 两个表
- 在字典中维持一个 索引计数器 rehashidx,设置为0,代表 rehash 操作正式开始
- 在 rehash 期间,每次对字典进行增删改查的时候,程序除了本身应该做的 增删改查运算,还会 顺带将 ht[0] 上的 rehashidx 索引的 键值对转移到 ht[1],当此次 rehash 操作过后,rehashidx 增加1
- 随着字典操作的不断执行,ht[0] 上所有键值对都会转移到 ht[1] 上,rehashidx 设置为 -1
- 当然,在 rehash 期间,肯定还会有对数据的 增删改查操作,如果是 删改查操作,则会同时操作 ht[0] 和 ht[1],而如果是 增加操作,则只能在 ht[1] 上
哈希表ht( 什么是hashtable )使用的是
链地址法解决 hash冲突问题,所以 dictEntry* 为链表结构,每个 dictEntry 节点都会有一个 next 属性存储 下一个节点位置,这里有个地方需要注意,每次链表上的节点插入都是 头插法;而 sizemask 属性的值用来计算 hash 值,决定放在 hashtable 的哪个位置上,一般属性值为 size - 1哈希表节点 dictEntry 的 v 属性支持多态性,多个字段可以存储 指针 / int / double 多种类型
字典 dict 中 type 和 privadata 属性 都是为 多态字典而设立的,type 属性结构体为 dictType,保存了一簇用于操作指定类型键值对的函数,而 privdata 属性则保存的需要传给 type 指定函数的 可选参数
下面我们就 Redis 字典的一些 典型的 API 进行解析~~~
源码解析
由于有些方法里的代码量比较大,我们这里按照 典型的代码片段进行解析,同志们可以根据文章提示的代码位置 和 代码里面的关键词 在源码中搜素,可能数据结构一些元素 看不太懂什么意思,没关系,先混个脸熟,后面看完回头再看过来就明白了
dict创建函数为 dictCreate(),主要逻辑为 申请空间、初始化 属性
添加键值对相关函数 dictAdd()、dictAddRaw()、dictReplace()
dictAdd() 为添加键值对主函数,dictAddRaw() 为添加只有 key 的键值对方便后续赋值
_dictKeyIndex() 获取 key 在 hashtable 所在的 索引地址
dictReplace() 函数 主要是将指定的键值对添加到字典里,如果键已经存在于字典中,那么新值取代原值
查找键值对相关函数 dictFind()、dictFetchValue()、dictGetRandomKey()
dictFind() 为查找 dictEntry 节点函数,dictFetchValue() 为查找值函数
dictGetRandomKey() 随机获取键值对
键值对相关函数 dictDelete()、dictDeleteNoFree()、dictGenericDelete()
dictDelete() 为节点删除主函数,不过实际执行函数为 dictGenericDelete()
|
|
字典删除相关函数 dictRelease()、_dictClear()
dictRelease() 为字典删除的主函数,主要逻辑为 清除 ht[0] 和 ht[1]、释放 字典,而 _dictClear() 为清除函数
rehash算法 主要有两种方式:
一种为 上面我们经常会提到的 跟随其他操作的 rehash,调用的是 _dictRehashStep() 函数,我们一般常用的还是这种
另外一种为 定时循环进行 rehash 操作,函数为 dictRehashMilliseconds()
不过无论哪种方式的 rehash 操作,最终还是调用了 dictRehash() 函数,返回 0 代表已经完全转移完毕,返回1 代表未转移完毕
本文作者: wettper
本文链接: http://www.web-lovers.com/redis-source-dict.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!

